But as the mining industry evolves, its demand for data also grows. Increasingly, geotechnical data, such as rock mass quality, fracture patterns and structural integrity, has become just as critical as assay data. Whether designing underground or open-pit mines, engineers now depend heavily on understanding the mechanical behaviour of rock mass. And yet, geostatistical techniques originally developed for grade modelling often fall short or fail when applied to geotechnical parameters.
Why geotechnical block modelling is different
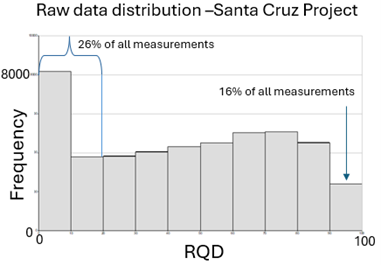
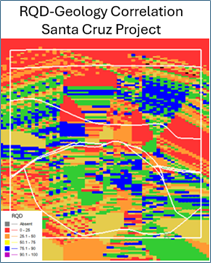
The problem is rooted in data behaviour. Grade data typically exhibits smoother spatial patterns and lends itself to statistical interpolation. Geotechnical data doesn’t. Parameters like rock quality designation (RDQ), Q-values and fracture frequency often change abruptly because of faults, joints, lithological contacts and other structural features.
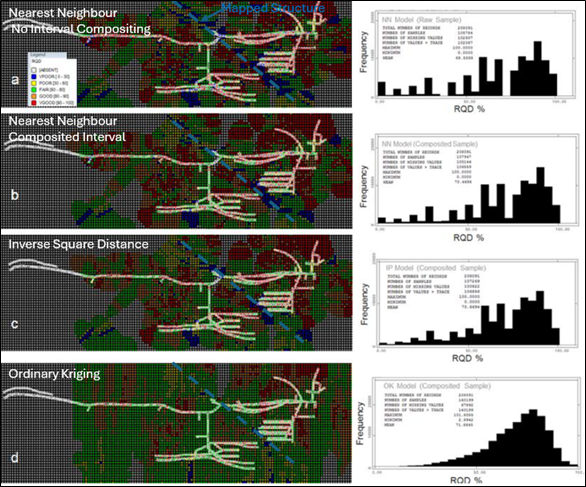
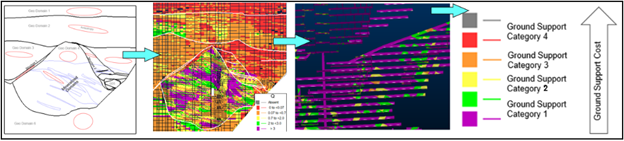
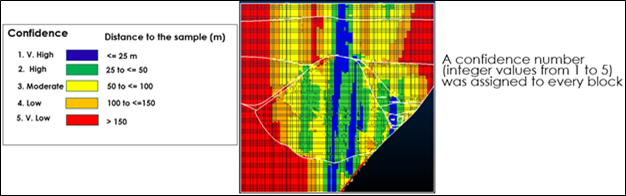
When geostatistical methods are applied blindly to the geotechnical data, the model may look statistically sound, but can distort key structural features. This misrepresentation can lead to flawed support design, safety risks and costly planning errors. As one example illustrates, a model that is geostatistically “perfect” may completely miss a major fault zone, rendering it geotechnically useless. As shown in the image below, simply reusing the same methodology can grossly distort geotechnical data and erase important geological and geotechnical truths. The model at the bottom is geostatistically correct but geotechnically obsolete because it lost all trace of a major structure in between.